eDiAna
General Information, Preface and Acknowledgements
About the Project
The Digital Philological-Etymological Dictionary of the Minor Anatolian Corpus Languages (eDiAna) came into being as a cooperative project sponsored by the Deutsche Forschungsgemeinshaft (HA 3372/7-1 und HA 3372/7-3, MI 1409/3-1 und MI 1409/3-3, RI 1730/7-1 und RI 1730/7-3). Its goal is to provide the first exhaustive lexical assessment of the entire corpus of the lesser attested ancient Anatolian languages, i.e. Luwian (in cuneiform and hieroglyphic transmission), Lycian (A and B), Carian, Lydian, Palaic, Sidetic, and Pisidian. This includes the philological documentation of synchronic word usage as well as the etymological component, linking the lexical stock of the languages mentioned above to that of Hittite and the other Indo-European languages. The Digital Philological-Etymological Dictionary of the Minor Language Corpora of Ancient Anatolia is intended to serve as a fundamental reference tool for Hittitology and for Ancient Anatolian and Ancient Near Eastern Studies as well as for Indo-Europeanists. The complete dictionary is available online and its use is free of charge.
LemmataThe main structural unit of the eDiAna project is the lemma. Most synchronic dictionary lemmata are headed by specific Anatolian lexemes and have a uniform structure. The general information about the textual transmission of a lexeme is followed by the list of its paradigmatic forms with attestations, survey of its special graphic features (where applicable), semantic discussion, list of derivatives, discussion of stem formation, and finally internal reconstruction (where applicable). The synchronic lemmata of the derivatives (including compounds) are linked to the base lemmata and vice versa. The diachronic lemmata (always headed by Proto-Anatolian or dialectal Anatolian reconstructions with asterisks) represent collections of etymologically related synchronic lemmata, which in addition are endowed with the discussion of their comparative reconstruction, Hittite cognates, and further Indo-European etymologies (where available). The Indo-European etymological sections feature the lists of cognates and subsections devoted to the semantic and morphological reconstruction. The synchronic lemmata are linked to their umbrella diachronic lemmata, and vice versa.
InterfaceThe Dictionary, Corpus and Literature interfaces can be independently accessed from the main menu (see the upper ribbon). The Dictionary interface, which grants access to the core of eDiAna, features a variety of lemma search options. Those already familiar with the ID number of a particular lemma can simply type it in. Alternatively, one can search for the lexemes constituting headwords with prompts from the dictionary. Finally, it is possible to select a lemma from a lexical list of a particular language. Additional options are searching for specific word-forms and full-text search. The distinct peculiarity of the present dictionary is its corpus-based character: all the Hieroglyphic Luwian, Lycian (A and B), Carian, Sidetic and Pisidian forms listed in the lemmata are linked to their contextual attestations in the corpora (the Cuneiform Luwian and Palaic lemmata are not, because the respective corpora are developed within the framework of other projects). At the same time, the Corpus interface provides a direct way of searching and browsing through the eDiAna corpora. Thus, it is possible to select inscriptions from the list of their names (sigla) and see their full texts, where all the forms are glossed and annotated for their morphological features. Furthermore, it is possible to search the language corpora for lemmata, translations, and grammatical features. Another special feature of the dictionary is the interactive bibliography: each bibliographic reference is linked to the lemmata where it has been used. It is possible to search for bibliographic entries and trace their impact on the dictionary via the Literature interface.
Division of Labor and ResponsibilityThe dictionary has four editors: Olav Hackstein (Munich), Jared Miller (Munich), Elisabeth Rieken (Marburg), and Ilya Yakubovich (Moscow – Marburg). The first three editors led the three modules of the eDiAna project, responsible for the Indo-European reconstruction, Cuneiform Luwian / Carian / Sidetic languages, and the other languages covered by the project respectively. The fourth editor coordinated the work on the corpora and their integration into the dictionary. A number of other linguists and philologists acted as members of the eDiAna project and wrote lemmata for the dictionary (for details, see under Team). The role of the editors was limited to designing the architecture of the dictionary (in cooperation with the Digital Development Module) and moderating the discussion of linguistic conventions (such as transliterations). All the sections of each lemma bear sigla indicating their respective authors, and individual project members (including the editors) retain full responsibility for the content of their signed texts. We encourage the citation of individual authors in connection with their lemmata, while the editors should only be mentioned if the dictionary is cited as a whole (cf. the precise citation Guidelines). In many instances, the original discoveries made in the course of the project and cross-referenced in the lemmata are presented in more detail in the separate publications by the project members. In such instances, the citation of the original sources remains preferable. Also, the updated corpus is not citable as such because it is based on the eDiAna lemmata, which may have been written by different authors. Instead, the lemmata themselves should be cited.
Timeline and VersioningThe first stage of the eDiAna project started in November 2014 and ended in October 2017. Its results included the initial form of the interface (previous version), the preparation of all the corpora and a limited number of lemmata. The second stage began in October 2018, continues until now, and focuses on lemma production and the elaboration of the interface. It is assumed that the project will officially end in June 2022, but lemmata will continue to be published regularly beyond this point. For the time being, one can access an intermediate portion of the dictionary, which still misses some of the planned lemmata and the updated versions of the corresponding corpora. The readings and grammatical interpretations of individual forms, their assignment to lexemes, and even lexical representations may undergo changes. The updated corpora will be released successively, once the synchronic dictionary of a given language is complete. Yet, given that lemmatization involves original research in the context of our project and thus leaves room for disagreement, the earlier versions of the text corpora and lemmata will be archived and can be retrieved for comparison if needed.
- Dictionary Entries: 3813
- Corpus Size: 38101 words / 942 texts
- Literature Database: 5021 datasets
Maps of (Ancient) Anatolia
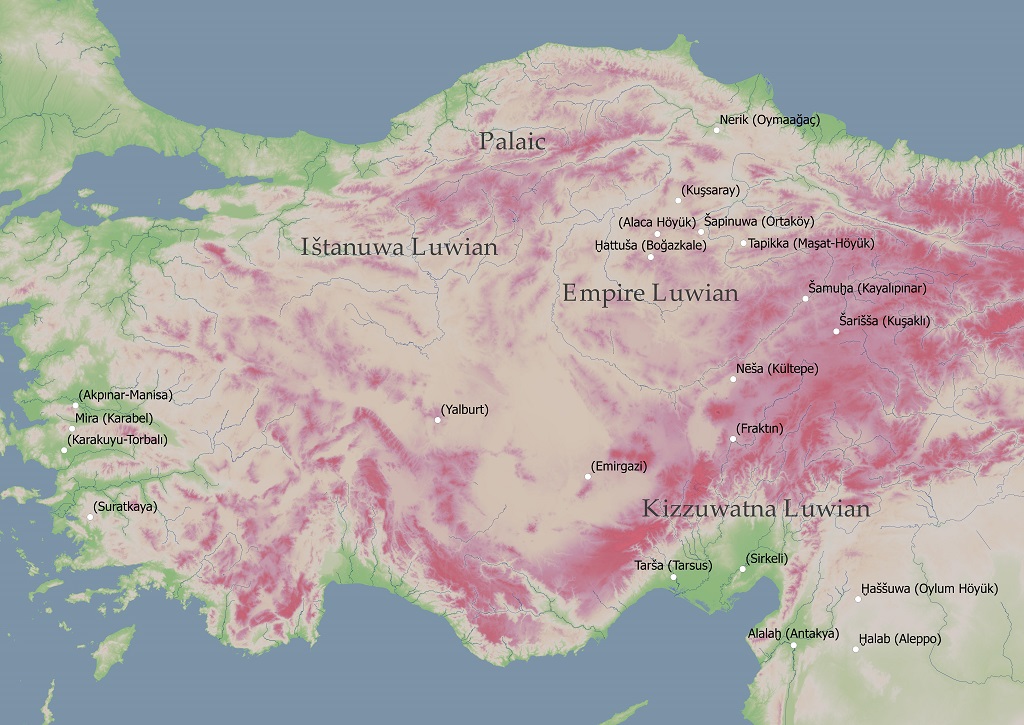
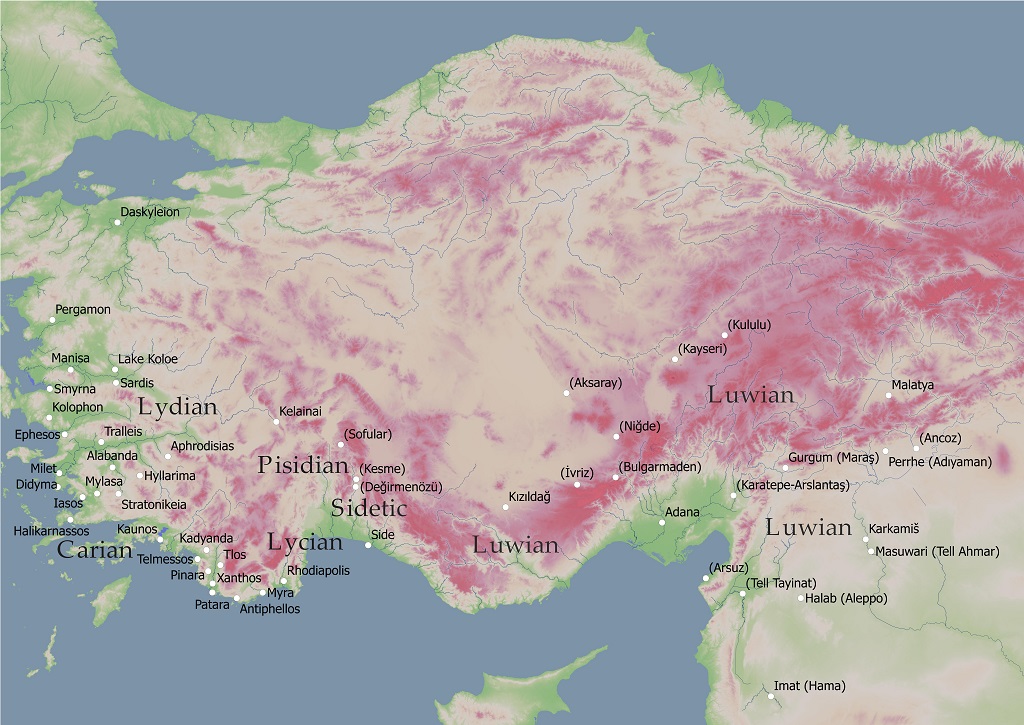
Module 1: Synchronic Lexicon of Cuneiform Luwian, Carian and Sidetic
Prof. Dr. Jared Miller, Dr. Anja Busse, Dr. Zsolt SimonThis module prepares and contributes to the synchronic dictionaries of three Anatolian languages and collects other miscellaneous forms. The scope of the dictionary consists of the lexemes of the individual languages. However, purely onomastic material has been taken into account only for the purpose of reconstructing otherwise unattested lexemes. The languages and categories are as follows:
1. Luwian in cuneiform transmission. This includes several corpora: traditionally, “Cuneiform Luwian” refers to Luwian words in texts written in Luwian or in Hittite, but this is linguistically inadequate, since the language and origin of (assumed) Luwian words in Hittite clauses and phrases requires a linguistic evaluation. This applies also to the group of the so-called Glossenkeilwörter. Additionally, Luwian words also appear in or can be reconstructed from other cuneiform corpora (Luwian material in cuneiform transmission [including personal names] is currently attested from the 20/19th c. until the 6th c. BCE). Thus, the following sub-categories are distinguished in the present dictionary:
- Cuneiform Luwian: words in Luwian clauses and phrases (in collaboration with Modul 2).
- Luwian in Hittite transmission: words in Hittite clauses and phrases that have been identified as Luwianisms either in the secondary literature or here, but are never marked with a Glossenkeil (in collaboration with Modul 2).
- Glossenkeilwörter: words that appear at least once with the so-called gloss marker (= Glossenkeil) in Hittite texts (in collaboration with Modul 2).
- Luwian in Old Assyrian transmission: Luwian words that can be reconstructed from Anatolian names attested in Old Assyrian texts as well as Luwian words attested there directly.
- Luwian in Other Transmission: (reconstructed) Luwian words from any cuneiform transmission beyond the sub-categories above.The vocabulary of Luwian in hieroglyphic transmission is prepared in Module 2.
2. Carian (8th / 7th ‒ 4th / 3rd c. BCE, Western Anatolia and Egypt).
3. Sidetic (4th ‒ 3rd c. BCE, Southern Anatolia).
Miscellaneous:
- the material of the only marginally known members of the Anatolian branch (such as “Lycaonian”) and of those varieties that cannot be properly classified (e.g., “Arzawa Luwic”);
- the loanwords in the neighbouring Semitic, Indo-European, and other languages, following the established tradition of Hittite etymological dictionaries.

Module 2: Synchronic Lexicon of Cuneiform Luwian, Hieroglyphic Luwian, Palaic, Lycian, Lydian and Pisidian, and reconstructed *Proto-Anatolian
Prof. Dr. Elisabeth Rieken, Dr. Anna Henriette Bauer, Dr. David Sasseville, in collaboration with Dr. habil. Ilya YakubovichModule 2 is responsible for two aspects within the eDiAna project: synchronic lexicography, and Proto-Anatolian reconstruction. Within the lexicography part, we compile the synchronic dictionaries for the following Anatolian languages attested in the 2nd and 1st millennium B.C.E. and the first two centuries C.E.:
- Cuneiform Luwian (in collaboration with Module 1)
19th to 12th century B.C.E., Central Anatolia - Hieroglyphic Luwian
14th/13th to 7th century B.C.E., Anatolia and Northern Syria - Lycian
5th and 4th century B.C.E., South-Western Anatolia - Lydian
7th to 4th century B.C.E., Western Anatolia - Pisidian
1st and 2nd century C.E., Southern Anatolia
On the basis of the synchronic dictionaries compiled by Modules 1 and 2, we reconstruct Proto-Anatolian stems for those lemmata that occur in more than one of the ancient Anatolian languages and/or have cognates in any of the other Indo-European languages.

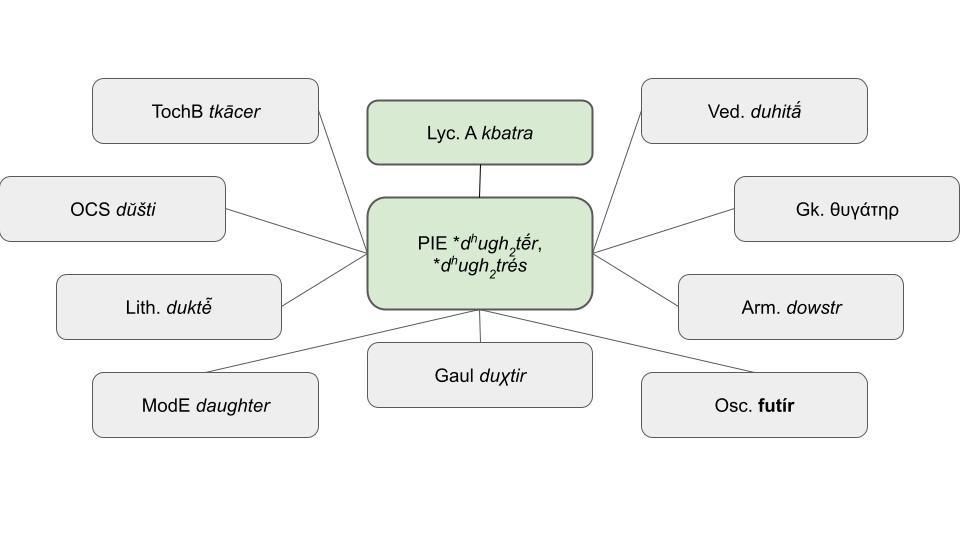
Module 3: Proto-Indo-European Etymology of the minor Anatolian Corpus Languages
Prof. Dr. Olav Hackstein, Dr. Andreas Opfermann, PD Dr. Thomas SteerThe aim of Module 3 is to provide a PIE etymology for the stems and roots that are continued in the minor Anatolian languages. Based on the inner-Anatolian reconstruction given by Module 2, we investigate the non-Anatolian Indo-European languages in search for cognates to reconstruct a common protoform.
By doing so, we focus, among others, on the following IE language branches and individual languages:
- Indo-Iranian (Vedic, Sanskrit; Avestan, Old Persian, etc.)
- Greek (Mycenaean, Ancient Greek)
- Armenian
- Italic (Latin, Oscan, Umbrian, etc.)
- Celtic (Irish, Welsh, Breton, etc.)
- Germanic (Gothic, Old Norse, Old English, Old High German, etc.)
- Baltic (Lithuanian, Latvian, Old Prussian)
- Slavic (Old Church Slavonic, Russian, Bulgarian, Czech, etc.)
- Tocharian (Tocharian A and B)
- Albanian
On the basis of the etymological dictionaries of these languages, articles, monographs, and further literature we then compile our dictionary entries. They usually consist of a list of words and forms that are cognate with the Anatolian material discussed by Module 2, followed by some remarks on the PIE semantics, and a morphological discussion dealing with the PIE root and derivational processes involved. If it is possible to reconstruct related PIE phraseology or syntax, this is added in the last section of the lemma.
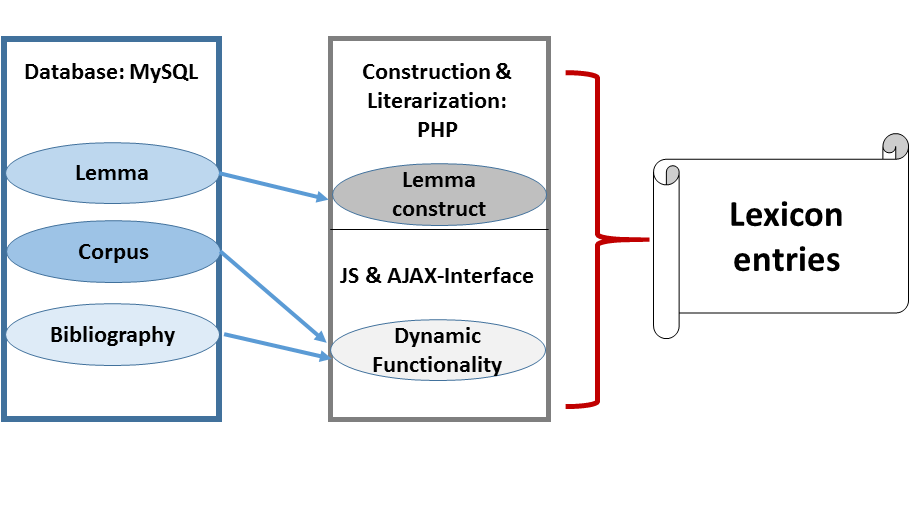
Digital Development
Christiane Bayer M.A., in collaboration with Dr. Tobias Englmeier and Dr. Markus FrankThis project attempts to do justice to the new opportunities of the Digital Humanities: as our ultimate objective, we regard a philological-etymological dictionary that is convenient to operate and adjustable to the individual requirements.
The entire project (under CC license) is hosted on the servers of the IT Group for the Humanities-Department of the Ludwig Maximilians University of Munich. In the first phase of the project, Dr. Markus Frank developed the conception, designed the database (MySQL) and programmed the prototype of eDiAna. The second project phase (November 2018 to January 2022) fell under the responsibility of Christiane Bayer, who further developed the existing structure successively and adapted it to the data, ensuring usability. Special thanks are due to Dr. Tobias Englmeier and the IT Group for the Humanities at LMU (under the direction of Dr. Christian Riepl) for their support in programming, consulting and development.
The eDiAna project benefited from the cooperation with Birgit Christiansen, J. David Hawkins, and Annick Payne at the stage of compiling the text corpora (details). H. Craig Melchert contributed to the project not only through helpful advice at every stage of its implementation but also through sharing several preprint versions of his Dictionary of Cuneiform Luwian (DCL). The eDiAna workshop Current Research on Lycian (Munich, 16-17 February 2017) advanced the study of the Lycian lexicon for the benefit of the project. In addition, our work was facilitated through cooperation with several partner projects, the list of which is given immediately below.
The Editors
| Institution/Description | Link | |
|---|---|---|
| IT-Group for the Humanities (LMU). | ||
| Hethitologie-Portal Mainz: HPM. | ||
| Annotated Corpus of Luwian Texts Project of the Russian Academy of Sciences. Principal Investigator: Dr. habil. Ilya Yakubovich. |
||
| Das Corpus der hethitischen Festrituale: staatliche Verwaltung des Kulturwesens im spätbronzezeitlichen Anatolien Project of the Mainz Academy of Sciences and Literature. Principal Investigartors: Prof. Dr. Elisabeth Rieken and Prof. Dr. Daniel Schwemer. |
||
| Luwili: Luwian Religious Discourse between Anatolia and Syria Project of the Agence Nationale de la Recherche (France) and Deutsche Forschungsgemeinschaft (Germany). Principal Investigators: Dr. habil. Alice Mouton and Dr. habil. Ilya Yakubovich. |
||
| Los dialectos lúvicos del grupo anatolio en su contexto lingüístico, geográfico e histórico (2016–2018) and Los dialectos lúvicos del grupo anatolio: escritura, gramática, onomástica, léxico (2019–2022).
Prof. Dr. Ignacio Javier Adiego Lajara, Dr. Mariona Vernet Pons, and Dr. José Virgilio García Trabazo |